Wenn mehr und mehr kritische kommerzielle applikationen ihren weg in das Internet finden, wird das bereitstellen von hochverfügbaren Diensten zunehmend wichtig. Einer der Vorteile von einem Cluster System ist das es Hardware und Software Redundanz besitzt. Hochverfügbarkeit kann bereitgestellt werden durch das aufspüren von Node oder Daemon Fehlern und die angemessene Rekonfiguration des Systems so das die Arbeitslast von den verbleibenden Nodes in dem Cluster übernommen werden kann.
In wirklichkeit ist, hochverfügbarkeit ein sehr weites Feld. Ein elegantes hoch- verfügbarkeits System hat möglicherweise ein verlässliches Gruppen Kommunikations sub-system, Mitgliedschafts Management, "quoram sub-systems", concurrent control sub-system und so weiter. Da gibt es sehr viel Arbeit. Wie auch immer, wir können einige existierende Software benutzen, um nun ein hochverfügbarkeits LVS systems zu bauen. Da gibt es viele Methoden um ein hochverfügbarkeits LVS System zu bauen, bitte schreiben Sie mir eine Mitteilung wenn Sie eine elegante Methode herausgefunden haben. Die folgende zwei Methoden dienen nur als Referenz.
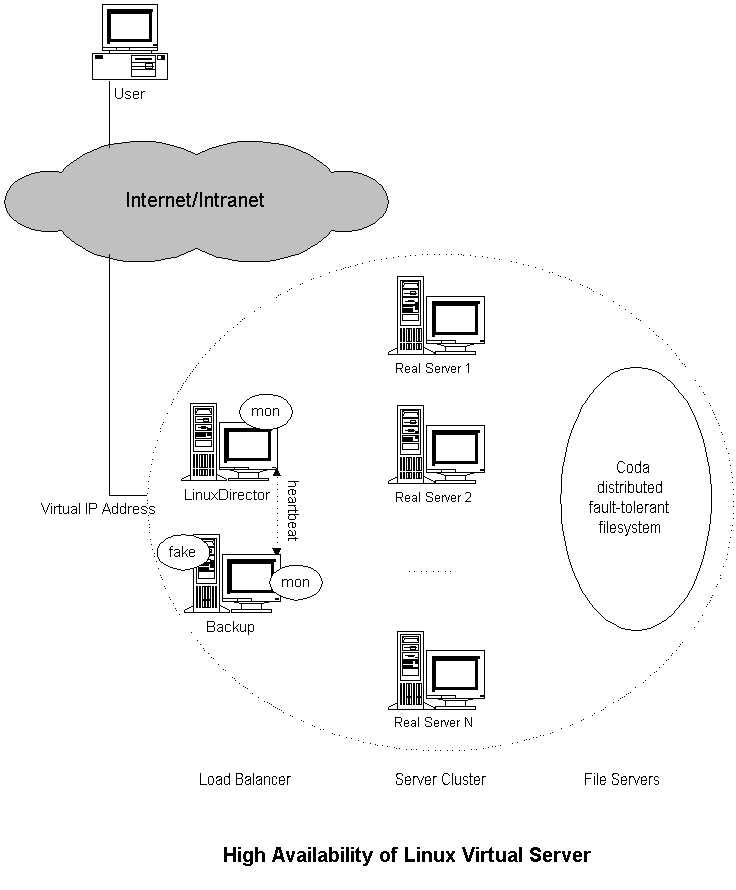
Die Hochverfügbarkeit eines Virtuellen Servers kann bereitgestellt werden durch Benutzung von "mon", "heartbeat" , "fake" und "coda" Software. Der "mon" ist ein allgemein benutzbares Ressourcen Monitor System, welches benutzt werden kann um Verfügbarkeit von Netzwerk Diensten und Server Nodes zu monitoren. Der "heartbeat" Code ermöglicht zur Zeit die heartbeats zwischen zwei Node Computern durch eine serielle Verbindung und UDP heartbeats. Fake ist IP Übernahme Software realisiert durch Manipulation der ARP Tabellen(spoofing). Die Hochverfügbarkeit eines Linux Virtual Servers ist illustriert in dem folgenden Bild.
Der Server Ausfall wird folgendermaßen abgehandelt: Der "mon" Daemon läuft auf dem Load Balancer um Service Daemons und Server Nodes in dem Cluster zu monitoren. Der fping.monitor ist konfiguriert aufzuspüren ob die Server Nodes jede t Sekunden noch lebendig sind, und der relative Service Monitor ist auch dafür konfiguriert die Dienst Daemons auf allen Nodes jede t Sekunden zu checken. Zum Beispiel, http.monitor kann benutzt werden um die http Dienste zu checken; ftp.monitor ist für die ftp Dienste, und so weiter. Ein Alarm wurde geschrieben um eine Regel in der Tabelle des Linux Virtual Server entfernen/hinzufügen während geprüft wird ob der Server Node oder Daemon down/up ist. Deshalb kann der Load Balancer automatisch Dienste Daemons oder Servers Ausfälle maskieren und sie wieder in den Dienst nehmen, wenn sie sich wieder zurückgemeldet haben.
Jetzt, wird unser Load Balancer ein einzelner Ausfallpunkt des gesamtem Systems. Der Auftrag des Maskierens des Ausfalls von dem primären Load Balancer, müssen wir nun durch das Aufsetzten eines Backup Load Balancers bewerkstelligen. Die "fake" Software wird für den Backup Server benutzt um die IP Adresse des primären Load Balancers zu übernehmen gesetzt den Fall, das er ausfällt. Und der "heartbeat" Code wird zum aufspüren des Status des primären Load Balancers benutzt um "fake" auf den backup Server zu aktivieren/deaktivieren. Zwei heartbeat Daemons laufen auf dem primären und den Backup, sie heartbeaten die Mitteilung wie "Ich bin noch lebendig(I'm alive)" jeder für sich durch die Serielle Leitung periodisch. Wenn der heartbeatcode Daemon nicht die "Ich bin noch lebendig(I'm alive)" von dem primären in der definierten Zeit hören kann, wird die fake Software aktiviert welche die Virtuelle IP Adresse übernimmt um den Load Balancing Dienst weiterhin zu ermöglichen. Wenn er die "Ich bin noch lebendig(I'm alive)" von dem primären später wieder bekommt deaktiviert er "fake" zur freigabe der Virtuellen IP Adresse, und der primäre kommt zu seiner eigendlichen Arbeit zurück.
Wie auch immer, der Ausfall oder die Übernahme des primären Load Balancers ist die Ursache das die etablierten Verbindungen in der Hash Tabelle der aktuellen Implementation verloren gehen, welches daher voraussetzt das Clients ihre Anfragen erneut abschicken müssen.
Coda ist ein Fehler tolerantes verteiltes Datei System, ein Abkömmling des Andrew Datei Systems. Der Content der Server kann in Coda abgelegt werden, so das Dateien hochverfügbar und leicht zu managen sind.
Das folgende ist ein Beispiel einen hochverfügbaren Virtuellen Webserver über Direct Routing aufzusetzen.
Der Ausfall von Real Servern
Der "mon" wird benutzt um Dienst Daemons und Server Nodes in dem
Cluster zu monitoren. z.B kann der fping.monitor benutzt werden um die Server
Nodes zu monitoren, http.monitor kann benutzt werden um die http Dienste zu
checken, ftp.monitor ist für die ftp Dienste, und so weiter. So, brauchen
wir nur einen Alarm zu generieren um eine Regel in der Virtual Server Tabelle
zu entfernen/hinzuzufügen wenn entdeckt wurde das der Server Node oder
Daemon down/up ist. Hier ist ein Beispiel genannt lvs.alert, welches einen virtuellen
Dienst(IP:Port) und den Dienst Port von Real Servern als Parameter nimmt.
|
Der lvs.alert wird abgelegt unter dem /usr/lib/mon/alert.d Ordner. Die mon Konfigurations Datei (/etc/mon/mon.cf oder /etc/mon.cf) kann folgendermassen konfiguriert werden um die die http Dienste und Server in dem Cluster zu Monitoren.
|
Bedenke, das Du die Parameter für lvs.alert folgendermassen angeben musst "lvs.alert -V 10.0.0.3:80 -R 192.168.0.3:8080" wenn der Ziel Port verschieden in LVS/NAT ist.
Nun kann der Load Balancer automatisch Dienst Daemons oder Server Ausfälle maskieren und sie wieder in den Dienst integrieren wenn sie sich zurück melden.
Der Ausfall des Load Balancers
Unser Auftrag zu verhindern das der Load Balancer ein einzelner Ausfallpunkt des gesammten Systems wird, müssen wir ein Backup des Load Balancers aufsetzen und sie untereinander periodisch heartbeaten lassen. Bitte lesen Sie das GettingStarted Dokument welches sich im Heartbeat Packet befindet, es ist sehr einfach ein 2-Node heartbeat System aufzusetzen.
Als ein Beispiel nehmen wir an, das die zwei Load Balancer die folgenden Adressen haben:
|
lvs1.domain.com (primary) |
10.0.0.1 |
|
lvs2.domain.com (backup) |
10.0.0.2 |
|
www.domain.com (VIP) |
10.0.0.3 |
Nach der Installation des heartbeat bei beiden lvs1.domain.com und lvs2.domain.com, erstelle einfach die /etc/ha.d/ha.conf folgendermassen:
|
Die /etc/ha.d/haresources Datei ist folgendermassen:
|
Die /etc/rc.d/init.d/lvs ist folgendermassen:
|
Zum Schluss, sei Dir sicher, das all die Dateien auf beiden den lvs1 und lvs2 Nodes erstellt worden sind, und ändere sie für deine eigene Konfiguration, dann starte den heartbeat Daemon auf den beiden Nodes.
Nimm zur Kenntnis das "fake" (IP übernahme durch Gratuitous Arp) schon in dem heartbeat Paket enthalten ist, so ist es nicht notwendig "fake" separat aufzusetzen. Wenn der lvs1.domain.com Node ausfällt, wird der lvs2.domain.com alle die haresources von dem lvs1.domain.com übernehmen. D.h. übernehmen der 10.0.0.3 Addresse druch Gratuitous ARP, starten des /etc/rc.d/init.d/lvs und /etc/rc.d/init.d/mon Skriptes. Wenn die lvs1.domain.com zurück kommt, gibt der lvs2 die HA resources wieder frei und der lvs1 nimmt sie zurück.
Der ldirectord (Linux Director Daemon) geschrieben von Jacob Rief ist ein stand-alone Daemon um Dienste von Real Servern zu monitoren, gegenwärtig http and https Dienste. Er ist einfach zu installieren und arbeitet mit dem heartbeat Code. Das ldirectord Program kann unter dem contrib Verzeichnis in dem ipvs tar ball gefunden werden, oder Du kannst das CVS Repositorium des heartbeat für die letzte Version checken. Siehe 'perldoc ldirectord' über all die Informationen von ldirectord. Dank an Jacob Rief für das Schreiben dieses grossartigen Programms!
Die Vorteile von ldirectord über mon sind folgende:
Der ldirectord ist speziell für das LVS
Monitoring geschrieben worden.
Er liest konfigurations Dateien wie /etc/ha.d/xxx.cf, welche alle Informationen
über die Konfiguration der IPVS Routing Tabellen enthalten. Wenn der
ldirectord läuft, wird die IPVS Routing Tabelle passend konfiguriert.
Du kannst auch verschiedene Virtuelle Dienst Konfigurationen in mehreren
konfigurations Dateien anlegen, so das es möglich wird einige Parameter
von einigen Diensten zu modifizieren ohne andere Dienste herunterfahren
zu müssen.
Der ldirectored kann leicht durch heartbeat gestarted und gestoppt werden.
Lege den ldirectord unter den /etc/ha.d/resource.d/ Ordner, dann kannst
du folgende Zeile in der /etc/ha.d/haresources Datei anlegen:
|
Jedenfalls, der ldirectord kann auch Manuell gestarted gestopped werden. Du kannst ihn in Deinem LVS cluster auch ohne den Backup Load Balancer benutzen.
Für das beispiel welches in der mon+heartbeat+fake+coda Lösung vorgestellt
wurde, kannst Du die /etc/ha.d/www.cf folgendermassen konfigurieren:
|
Die /etc/ha.d/haresources Datei ist folgendermassen einfach:
|
Du musst die .testpage Datei in den the DocumentRoot Verzeichnis von jedem
Webserver anlegen.
|
Starte die heartbeat Daemons auf den primären und den backup. Wenn da irgend etwas schief läuft, kannst Du die /var/log/ha-log beziehungsweise die /var/log/ldirector.log Datei checken.